CHÉM GIÓ, BÀN LUẬN VỀ KỸ THUẬT
Nhập môn cơ sở dữ liệu - Phần 4: Những ưu điểm trong hướng tiếp cận bằng hệ quản trị cơ sở dữ liệu
17 Tháng Năm 2021
Trong phần này, chúng ta thảo luận về một số lợi thế bổ sung của việc sử dụng DBMS và các khả năng mà một DBMS tốt cần có. Những khả năng này bổ sung cho bốn đặc điểm chính được thảo luận trong bài trước. DBA phải sử dụng các khả năng này để hoàn thành nhiều mục tiêu khác nhau liên quan đến thiết kế, quản trị và sử dụng cơ sở dữ liệu đa người dùng lớn

Controlling Redundancy
Trong phát triển phần mềm truyền thống sử dụng xử lý tệp, mỗi nhóm người dùng duy trì tệp của riêng mình để xử lý các ứng dụng xử lý dữ liệu của họ. Ví dụ, hãy xem xét ví dụ về cơ sở dữ liệu ĐẠI HỌC của bài trước; ở đây, hai nhóm người dùng có thể là nhân viên đăng ký khóa học và văn phòng kế toán. Theo cách tiếp cận truyền thống, mỗi nhóm lưu giữ các tệp tin về học sinh một cách độc lập. Văn phòng kế toán lưu giữ dữ liệu về đăng ký và thông tin thanh toán liên quan, trong khi văn phòng đăng ký theo dõi các khóa học và điểm của học sinh. Các nhóm khác có thể sao chép thêm một số hoặc tất cả cùng một dữ liệu trong các tệp của riêng họ
Sự dư thừa này trong việc lưu trữ cùng một dữ liệu nhiều lần dẫn đến một số vấn đề. Đầu tiên, cần phải thực hiện một cập nhật logic duy nhất — chẳng hạn như nhập dữ liệu về một sinh viên mới — nhiều lần: một lần cho mỗi tệp nơi dữ liệu sinh viên được ghi lại. Điều này dẫn đến sự trùng lặp. Thứ hai, không gian lưu trữ bị lãng phí khi cùng một dữ liệu được lưu trữ lặp đi lặp lại và vấn đề này có thể nghiêm trọng đối với cơ sở dữ liệu lớn. Thứ ba, các tệp đại diện cho cùng một dữ liệu có thể trở nên không nhất quán. Điều này có thể xảy ra vì bản cập nhật được áp dụng cho một số tệp nhưng không áp dụng cho những tệp khác. Ngay cả khi một bản cập nhật — chẳng hạn như thêm một sinh viên mới — được áp dụng cho tất cả các tệp thích hợp, thì dữ liệu liên quan đến sinh viên đó vẫn có thể không nhất quán vì các bản cập nhật được áp dụng độc lập bởi từng nhóm người dùng. Ví dụ: một nhóm người dùng có thể nhập sai ngày sinh của sinh viên là "JAN-19-1988", trong khi các nhóm người dùng khác có thể nhập giá trị chính xác là "JAN-29-1988".
Trong cách tiếp cận cơ sở dữ liệu, các khung nhìn của các nhóm người dùng khác nhau được tích hợp trong quá trình thiết kế cơ sở dữ liệu. Tốt nhất, chúng ta nên có một thiết kế cơ sở dữ liệu để lưu trữ từng mục dữ liệu logic — chẳng hạn như tên hoặc ngày sinh của học sinh — chỉ ở một nơi trong cơ sở dữ liệu. Đây được gọi là chuẩn hóa dữ liệu, nó đảm bảo tính nhất quán và tiết kiệm dung lượng lưu trữ

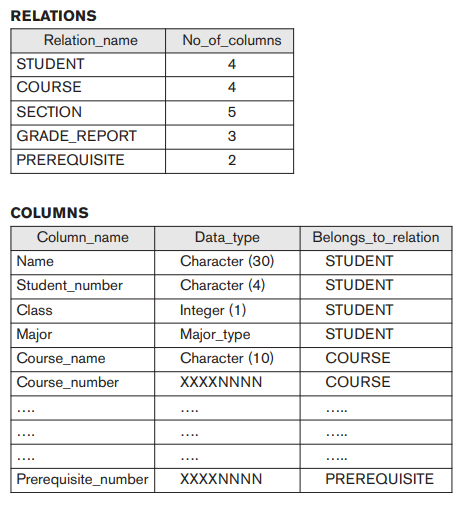
Tuy nhiên, trong thực tế, đôi khi cần sử dụng kỹ thuật có kiểm soát để cải thiện hiệu suất của các truy vấn. Ví dụ: chúng ta có thể lưu trữ dư thừa Student_name và Course_number trong tệp GRADE_REPORT (Hình dưới) vì bất cứ khi nào chúng ta truy xuất bản ghi GRADE_REPORT, chúng ta muốn truy xuất tên học sinh và số khóa học cùng với số lớp, số học sinh và mã định danh. Bằng cách đặt tất cả dữ liệu lại với nhau, chúng ta không phải tìm kiếm nhiều tệp để thu thập dữ liệu này. Điều này được gọi là không chuẩn hóa. Trong những trường hợp như vậy, DBMS phải có khả năng kiểm soát sự dư thừa này để ngăn chặn sự mâu thuẫn giữa các tệp. Điều này có thể được thực hiện bằng cách tự động kiểm tra xem các giá trị Student_name Student_number trong bất kỳ bản ghi GRADE_REPORT nào trong hình dưới khớp với một trong các giá trị Name-Student_number của bản ghi STUDENT. Tương tự, các giá trị Section_identifier – Course_number trong GRADE_REPORT có thể được kiểm tra đối với các bản ghi SECTION. Việc kiểm tra như vậy có thể được chỉ định cho DBMS trong quá trình thiết kế cơ sở dữ liệu và được DBMS tự động thực thi bất cứ khi nào tệp GRADE_REPORT được cập nhật. Hình (b) cho thấy một bản ghi GRADE_REPORT không phù hợp với tệp STUDENT trong Hình ở bài trước; loại lỗi này có thể được nhập nếu dự phòng không được kiểm soát. Bạn có thể cho biết phần nào là không nhất quán?
Restricting Unauthorized Access (Hạn chế truy cập trái phép)
Khi nhiều người dùng chia sẻ một cơ sở dữ liệu lớn, có khả năng là hầu hết người dùng sẽ không được phép truy cập tất cả thông tin trong cơ sở dữ liệu. Ví dụ: dữ liệu tài chính như tiền lương và tiền thưởng thường được coi là bí mật và chỉ những người có thẩm quyền mới được phép truy cập vào dữ liệu đó. Ngoài ra, một số người dùng có thể chỉ được phép truy xuất dữ liệu, trong khi những người khác được phép truy xuất và cập nhật. Do đó, loại hoạt động truy cập — truy xuất hoặc cập nhật cũng phải được kiểm soát. Thông thường, người dùng hoặc nhóm người dùng được cấp số tài khoản được bảo vệ bằng mật khẩu mà họ có thể sử dụng để truy cập vào cơ sở dữ liệu. DBMS phải cung cấp một hệ thống con bảo mật và ủy quyền, hệ thống này DBA sử dụng để tạo tài khoản và chỉ định các hạn chế tài khoản. Sau đó, DBMS sẽ tự động thực thi các hạn chế này. Lưu ý rằng chúng ta có thể áp dụng các điều khiển tương tự cho phần mềm DBMS. Ví dụ: chỉ nhân viên của DBA mới có thể được phép sử dụng một số phần mềm đặc quyền, chẳng hạn như phần mềm để tạo tài khoản mới. Tương tự, người dùng phổ thông chỉ có thể được phép truy cập cơ sở dữ liệu thông qua các ứng dụng được xác định trước hoặc các giao dịch đóng hộp được phát triển
Providing Persistent Storage for Program Objects
cơ sở dữ liệu có thể được sử dụng để cung cấp khả năng lưu trữ liên tục cho các đối tượng chương trình và cấu trúc dữ liệu. Đây là một trong những lý do chính của hệ thống cơ sở dữ liệu hướng đối tượng. Các ngôn ngữ lập trình thường có cấu trúc dữ liệu phức tạp, chẳng hạn như cấu trúc hoặc định nghĩa lớp trong C ++ hoặc Java. Giá trị của các biến hoặc đối tượng chương trình bị loại bỏ sau khi chương trình kết thúc, trừ khi người lập trình giải thích rõ ràng rằng nó sẽ lưu trữ chúng trong các tệp vĩnh viễn, thường liên quan đến việc chuyển đổi các cấu trúc phức tạp này thành một định dạng phù hợp để lưu trữ tệp. Khi phát sinh nhu cầu đọc dữ liệu này một lần nữa, người lập trình phải chuyển đổi từ định dạng tệp sang biến chương trình hoặc cấu trúc đối tượng. Hệ thống cơ sở dữ liệu hướng đối tượng tương thích với các ngôn ngữ lập trình như C ++ và Java, và phần mềm DBMS tự động thực hiện bất kỳ chuyển đổi cần thiết nào. Do đó, một đối tượng phức tạp trong C ++ có thể được lưu trữ vĩnh viễn trong một DBMS hướng đối tượng. Một đối tượng như vậy được cho là tồn tại lâu dài, vì nó vẫn tồn tại sau khi kết thúc thực thi chương trình và sau đó có thể được một chương trình khác truy xuất trực tiếp.
Việc lưu trữ liên tục các đối tượng chương trình và cấu trúc dữ liệu là một chức năng quan trọng của hệ thống cơ sở dữ liệu. Các hệ thống cơ sở dữ liệu truyền thống thường gặp phải vấn đề gọi là không khớp, vì cấu trúc dữ liệu do DBMS cung cấp không tương thích với cấu trúc dữ liệu của ngôn ngữ lập trình. Hệ thống cơ sở dữ liệu hướng đối tượng thường cung cấp khả năng tương thích cấu trúc dữ liệu với một hoặc nhiều ngôn ngữ lập trình hướng đối tượng.
Cung cấp cấu trúc lưu trữ và tìm kiếm. Kỹ thuật xử lý truy vấn hiệu quả
Hệ thống cơ sở dữ liệu phải cung cấp các khả năng để thực thi các truy vấn và cập nhật một cách hiệu quả. Vì cơ sở dữ liệu thường được lưu trữ trên ổ cứng, DBMS phải cung cấp các cấu trúc dữ liệu chuyên biệt và các kỹ thuật tìm kiếm để tăng tốc độ tìm kiếm trên ổ cứngcho các bản ghi mong muốn. Các tệp phụ trợ được gọi là chỉ mục thường được sử dụng cho mục đích này. Các chỉ mục thường dựa trên cấu trúc dữ liệu dạng cây hoặc cấu trúc dữ liệu băm được sửa đổi phù hợp để tìm kiếm trên ổ cứng. Để xử lý các bản ghi cơ sở dữ liệu cần thiết bởi một truy vấn cụ thể, các bản ghi đó phải được sao chép từ ổ cứng vào bộ nhớ chính. Do đó, DBMS thường có một mô-đun đệm hoặc bộ nhớ đệm để duy trì các phần của cơ sở dữ liệu trong các bộ đệm bộ nhớ chính. Nói chung, hệ điều hành có khả năng phục hồi để đệm ổ cứng vào bộ nhớ. Tuy nhiên, vì bộ đệm dữ liệu rất quan trọng đối với hiệu suất của DBMS, nên hầu hết các DBMS đều thực hiện bộ đệm dữ liệu của riêng chúng.
Mô-đun xử lý và tối ưu hóa truy vấn của DBMS chịu trách nhiệm chọn một kế hoạch thực thi truy vấn hiệu quả cho mỗi truy vấn dựa trên cấu trúc lưu trữ hiện có. Việc lựa chọn chỉ mục nào để tạo và duy trì là một phần của thiết kế và điều chỉnh cơ sở dữ liệu vật lý, đây là một trong những trách nhiệm của nhân viên DBA
Cung cấp Sao lưu và Phục hồi
DBMS phải cung cấp các phương tiện để khôi phục từ các lỗi phần cứng hoặc phần mềm. Hệ thống con sao lưu và phục hồi của DBMS chịu trách nhiệm khôi phục. Ví dụ: nếu hệ thống máy tính bị lỗi giữa một giao dịch cập nhật phức tạp, hệ thống con phục hồi có trách nhiệm đảm bảo rằng cơ sở dữ liệu được khôi phục về trạng thái trước khi giao dịch bắt đầu thực hiện. Sao lưu ổ cứng cũng cần thiết trong trường hợp ổ cứng bị lỗi nghiêm trọng
Cung cấp nhiều giao diện người dùng
Vì nhiều kiểu người dùng với các mức độ hiểu biết kỹ thuật khác nhau sử dụng cơ sở dữ liệu, nên DBMS phải cung cấp nhiều giao diện người dùng khác nhau. Chúng bao gồm các ứng dụng cho người dùng di động, ngôn ngữ truy vấn cho người dùng thông thường, giao diện ngôn ngữ lập trình cho người lập trình ứng dụng, biểu mẫu và mã lệnh cho người dùng tham số và giao diện hướng menu và giao diện ngôn ngữ tự nhiên cho người dùng độc lập. Cả giao diện kiểu biểu mẫu và giao diện hướng menu thường được gọi là giao diện người dùng đồ họa (GUI). Nhiều ngôn ngữ và môi trường chuyên biệt tồn tại để chỉ định GUI. Khả năng cung cấp giao diện Web GUI cho cơ sở dữ liệu — hoặc hỗ trợ cơ sở dữ liệu Web — cũng khá phổ biến.
Thể hiện cho các mối quan hệ phức tạp giữa các dữ liệu
Một cơ sở dữ liệu có thể bao gồm nhiều loại dữ liệu có liên quan với nhau theo nhiều cách. Hãy xem xét ví dụ trong hình trên. Bản ghi cho ‘Brown’ trong tệp STUDENT liên quan đến bốn bản ghi trong tệp GRADE_REPORT. Tương tự, mỗi bản ghi SECTION có liên quan đến một hồ sơ khóa học và một số bản ghi GRADE_REPORT — một bản ghi cho mỗi học sinh đã hoàn thành phần đó. Một DBMS phải có khả năng đại diện cho nhiều mối quan hệ phức tạp giữa dữ liệu, để xác định các mối quan hệ mới khi chúng phát sinh, đồng thời truy xuất và cập nhật dữ liệu liên quan một cách dễ dàng và hiệu quả.
Thực thi các ràng buộc
Hầu hết các ứng dụng cơ sở dữ liệu có các ràng buộc toàn vẹn dữ liệu. DBMS phải cung cấp các khả năng để xác định và thực thi các ràng buộc này. Loại ràng buộc toàn vẹn đơn giản nhất liên quan đến việc chỉ định một kiểu dữ liệu cho mỗi mục dữ liệu. Ví dụ, trong hình dưới, chúng ta đã chỉ định rằng giá trị của mục dữ liệu GRADE trong mỗi bản ghi STUDENT phải là số nguyên có một chữ số và giá trị của NAME phải là một chuỗi không quá 30 ký tự chữ cái. Để hạn chế giá trị của GRADE từ 1 đến 5 sẽ là một ràng buộc bổ sung không được hiển thị trong danh mục hiện tại. Một loại ràng buộc phức tạp hơn thường xuyên xảy ra liên quan đến việc chỉ định rằng một bản ghi trong một tệp phải liên quan đến các bản ghi trong các tệp khác. Ví dụ, trong Hình b, chúng ta có thể chỉ định rằng mọi bản ghi SECTION phải liên quan đến một bản ghi COURSE. Điều này được gọi là một toàn vẹn tham chiếu. Một loại ràng buộc khác chỉ định tính duy nhất trên các giá trị mục dữ liệu, chẳng hạn như mọi bản ghi khóa học phải có một giá trị duy nhất cho Course_number. Điều này được gọi là một khóa hoặc ràng buộc duy nhất. Những ràng buộc này bắt nguồn từ ý nghĩa hoặc ngữ nghĩa của dữ liệu và của thế giới nhỏ mà nó đại diện. Người thiết kế cơ sở dữ liệu có trách nhiệm xác định các ràng buộc toàn vẹn trong quá trình thiết kế cơ sở dữ liệu. Một số ràng buộc có thể được chỉ định cho DBMS và được thực thi tự động. Các ràng buộc khác có thể phải được kiểm tra bằng các chương trình cập nhật hoặc tại thời điểm nhập dữ liệu. Đối với các ứng dụng lớn điển hình, thường gọi các ràng buộc như vậy là các quy tắc nghiệp vụ.
Một mục dữ liệu có thể được nhập sai và vẫn đáp ứng các ràng buộc toàn vẹn đã chỉ định. Ví dụ: nếu một học sinh nhận được điểm ‘A’ nhưng điểm ‘C’ được nhập vào cơ sở dữ liệu, thì DBMS không thể tự động phát hiện ra lỗi này vì ‘C’ là giá trị hợp lệ cho kiểu dữ liệu Điểm. Những lỗi nhập dữ liệu như vậy chỉ có thể được phát hiện theo cách thủ công (khi học sinh nhận điểm và khiếu nại) và sửa chữa sau đó bằng cách cập nhật cơ sở dữ liệu. Tuy nhiên, cấp ‘Z’ sẽ tự động bị DBMS từ chối vì ‘Z’ không phải là giá trị hợp lệ cho kiểu dữ liệu GRADE
Permitting Inferencing and Actions using Rules and Triggers
Một số hệ thống cơ sở dữ liệu cung cấp khả năng xác định các quy tắc suy luận để suy ra thông tin mới từ các dữ kiện cơ sở dữ liệu được lưu trữ. Hệ thống như vậy được gọi là hệ thống cơ sở dữ liệu suy diễn. Ví dụ, có thể có những quy tắc phức tạp trong ứng dụng thế giới nhỏ để xác định thời điểm một sinh viên đang trong thời gian quản chế. Các quy tắc này có thể được chỉ định một cách khai báo dưới dạng các quy tắc, khi được biên soạn và duy trì bởi DBMS có thể xác định tất cả các sinh viên đang trong thời gian tập sự. Trong một DBMS truyền thống, một mã chương trình thủ tục (procedure) rõ ràng sẽ phải được viết để hỗ trợ các ứng dụng như vậy. Nhưng nếu các quy tắc của thế giới nhỏ thay đổi, nói chung sẽ thuận tiện hơn để thay đổi các quy tắc khấu trừ đã khai báo hơn là mã hóa lại các chương trình thủ tục. Trong các hệ thống cơ sở dữ liệu quan hệ ngày nay, có thể kết hợp trigger với các bảng. Trigger là một dạng quy tắc được kích hoạt bởi các bản cập nhật cho bảng, dẫn đến việc thực hiện một số hoạt động bổ sung cho một số bảng khác, gửi tin nhắn, v.v. Các biện pháp proce liên quan nhiều hơn để thực thi các quy tắc thường được gọi là các thủ tục được lưu trữ; chúng trở thành một phần của định nghĩa cơ sở dữ liệu tổng thể và được gọi một cách thích hợp khi đáp ứng các điều kiện nhất định. Chức năng mạnh mẽ hơn được cung cấp bởi các hệ thống cơ sở dữ liệu đang hoạt động, cung cấp các quy tắc hoạt động có thể tự động bắt đầu các hành động khi các sự kiện và điều kiện nhất định xảy ra
Tạm kết
Trong bài viết này chúng ta đã tìm hiểu về các ưu điểm trong việc tiếp cận bằng cơ sở dữ liệu. Chúc bạn đọc vui vẻ